

SmallRuby: nová implementace Ruby z ČVUT, napsaná ve Smalltalku
Jak známo, Ruby patří k jazykům, které mají poměrně hodně implementací. Jejich seznam se přibližně před rokem a půl stabilizoval a najdete ho třeba v mé diplomce (sekce 2.5). Bylo proto pro mě velkým překvapením, když jsem objevil implementaci novou – SmallRuby. Ještě větší překvapení následovalo, když jsem zjistil, že pochází z ČVUT.
Co je SmallRuby?
SmallRuby je implementace Ruby v prostředí Smalltalk/X. Její základ vznikl jako diplomová práce Jana Karpíška, studenta ČVUT. Podle projektového webu a podcastu jde ale o týmový projekt pod vedením Jana Vraného.
Hlavní motivací pro vznik SmallRuby byl nízký výkon původní implementace Ruby (MRI). To je dlouho známý problém (i když aktuální verze Ruby 1.9 ho alespoň částečně řeší). SmallRuby výkon zvyšuje překladem kódu v Ruby do bajtkódu smalltalkového virtuálního stroje. Ten je pak spouštěn a optimalizován stejným způsobem, jako kdyby byl původní kód napsán přímo ve Smalltalku – a běží tedy ve výsledku poměrně rychle.
Idea SmallRuby je velmi podobná projektu MagLev, který dělá v podstatě totéž, ale s jiným smalltalkovým virtuálním strojem, a navíc přidává podporu distribuovaného stavu a výpočtů. SmallRuby se snaží využít prostředí Smalltalku jiným způsobem a například přidává integraci Ruby do jeho vývojového prostředí:
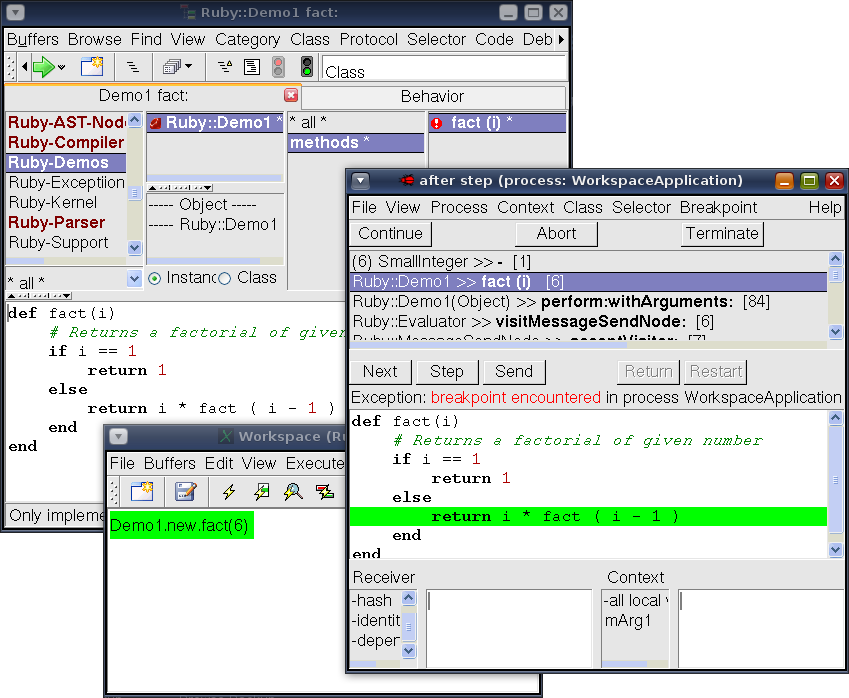
Ruby a smalltalkové nástroje. Převzato z webu SmallRuby.
Přirozené spojení
Využití Smalltalku pro implementaci Ruby je poměrně přirozené, protože oba jazyky jsou si poměrně podobné (oba jsou čistě objektové a používají třídy a dědičnost). Ruby je ale o něco dynamičtější, což při implementaci SmallRuby podle autorů způsobilo nemalé problémy. Některé jeho vlastnosti nebyly kvůli nekompatibilitě jazyků zatím implementovány vůbec.
Pokud vás zajímají detaily (mě zajímaly moc :-), doporučuji si přečíst přímo zmiňovanou diplomovou práci. Je sice místy obtížně srozumitelná a sloh zřejmě není autorovou silnou stránkou, nicméně to podstatné z ní lze pochopit bez větších problémů.
Výkon
Pokud byl motivací SmallRuby výkon, je na místě se ptát, zda se projektu opravdu podařilo Ruby zrychlit. Odpověď je ano. Autoři se na webu chlubí grafem, který ukazuje rychlost běhu některých standardních rychlostních testů, které obsahuje přímo původní implementace Ruby:
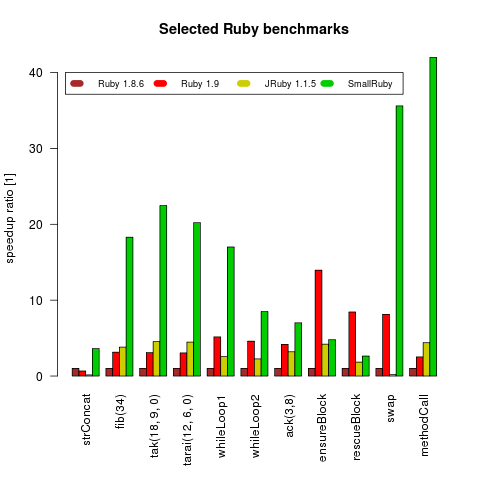
Graf srovnávající SmallRuby a vybrané další implementace Ruby. Převzato z webu SmallRuby.
Jak je vidět, SmallRuby je podstatně rychlejší než Ruby 1.8, a to až 40×. Podobně je tomu s JRuby. Ruby 1.9 předežene až na dva testy spolehlivě také. Zajímavé by bylo ještě srovnání s dalšími implementacemi a také s novější verzí JRuby (verze v grafu je přibližně rok stará).
Nutno dodat, že nejsou spouštěny zdaleka všechny testy ze sady, protože v některých se vyskytují konstrukce, které SmallRuby v tuto chvíli nepodporuje.
Závěr
SmallRuby je rozhodně zajímavý projekt – pro nás o to víc, že pochází z českých luhů a hájů. V současné době ale podporuje jen malou podmnožinu jazyka Ruby – autoři se zatím téměř vůbec nezabývali jeho běhovou knihovnou a vynechali i některé jazykové konstrukce. Pokud mají v SmallRuby jít spustit reálné programy, je potřeba na těchto oblastech zapracovat.
I pokud by SmallRuby podporovalo dostatečně velkou podmnožinu jazyka Ruby, je otázka, zda má reálné praktické využití. Dovedu si totiž jen obtížně představit, že si někdo bude například na server instalovat smalltalkový virtuální stroj jen kvůli tomu, aby zvýšil výkon implementace Ruby – zvlášť pokud Smalltalk nezná. Na druhou stranu není až tak nereálná třeba varianta, že se Ruby časem stane skriptovacím jazykem pro Smalltalk/X podobně, jako se Groovy, JRuby a další staly skriptovacími jazyky pro Javu/JVM.
Autorům s projektem každopádně přeji mnoho zdaru – sám moc dobře vím, jak je těžké alespoň trochu použitelnou implementaci Ruby vytvořit a kolik práce ještě mají před sebou, pokud SmallRuby chtějí dotáhnout k reálné použitelnosti.